


Before getting into encodeURI(), let's see what is meant by the term 'encoding'!!
Encoding simply means changing the form of data.Now, the question arises that why encoding is needed and how is it helpful!?
So, encoding is needed to ensure that the data which you're sending remains secure.The purpose of encoding is to transform the data from one form to another so that it can be properly and safely consumed by a different system.
Encoding keeps your data safe since the files are not readable unless you have access to the algorithms that were used to encode the data.
Now, there are some few terms to which i think that it's good for you to know besides encoding.
- Character set
- Unicode
- Unicode encoding(UTF-16, UTF-32, UTF-8)
- ASCII
- Surrogate pairs
Now, to understand what 'character set' is!?, let's take some few random languges from all over the world. So, here're some few languages that i picked up. You can stare at any of the languages of your choice.

Now in this big world there are thousand of languages. In the above image, i have picked up some few characters of some different languages. My apologies, if i have missed any of your favourite language.
The collection of so called character list like this is called character set.
So basically, a character set is a collection of characters that might be used by multiple languages.
Now, what does the term ASCII means!? ASCII is a character encoding which uses numeric codes to represent characters.These include uppercase and lowercase case English letters, numbers and punctuation symbols. Let's just move onto unicode.
Now, what does the term 'unicode' means!? So, Unicode is an evolving character set, that aims to cover all the written forms of languages.The unicode data can be represented in several forms(such as, UTF-8, UTF-16, UTF-32, etc.)
Earlier, all that existed was ASCII and it was all okay for earlier as all that was ever needed was few control characters, punctuations, letters, and letters, etc. But today the documentation of any social platform comprises more than one language in the same document. Now here the problem arises is that the ASCII wasn't made overseeing today's global communication and social media.
Therefore, to overcome this problem an encompassing character set including all languages would be needed.Thus came unicode.
Unicode assigns every character a unique number called a code point.And to access these character sets you need character encoding.
Now, comes unicode encoding. So, what does 'unicode encoding' actually mean!?
Unicode encoding is a lot just more simpler than people make it out today. So, let's just see what it is.
As discussed, unicode is a collection of characters or to more precissely say it's a colllection of symbols.Basically, every symbol you see online is a part of a unicode standard. And there's still about a miilion empty slots available.
You can take a look here: Unicode codepoints . This is really a great website with unicode characters.Click on any of the characters or symbols to see their unicode number.
Every symbol in unicode has a code point.This is its index; its identifier.
 Let's understand this with an example. Suppose, you text your friend or colleague with a message:
Let's understand this with an example. Suppose, you text your friend or colleague with a message:
Hi 😊
This would be stored as:
 So, how do we store this in binary!?
So, how do we store this in binary!?
 In this above example, i have coloured each codepoint to know the start nd end of each unicode.
But when computer recieve it, how do computer read it!? How do computer gets to know where do these symbols stop and start!?
In this above example, i have coloured each codepoint to know the start nd end of each unicode.
But when computer recieve it, how do computer read it!? How do computer gets to know where do these symbols stop and start!?
To solve this, we need fixed chunk sizes. And unicode allows for codepoints as large as 21 bits. But, computers are generally faster with the powers of '2', so let's use '32' instead.
Therefore, we came up with UTF-32 aka VCS-4.
VCS-4 says, 'hey, use only 4 bytes'.
As we know, 1 byte = 8 bits. therefore, 4 bytes = 32 bits. This is the reason why UTF-32 is also known as VCS-4.
Now, let's just try to encode the same text 'Hi 😊' using UTF-32.
 As you can see how much of the space is wasted.This wasn't space efficient and we're wasting so much space. Now, looking to it '21' bits seems much better.
As you can see how much of the space is wasted.This wasn't space efficient and we're wasting so much space. Now, looking to it '21' bits seems much better.
So, all we need is to encode text efficiently. We need to be space efficient. We can't encode text like this.
Let's go smaller than '32'
Let's go smaller than '21'
Let's go to '16'!
Which leads to introducing UTF-16 aka VCS-2.
Before the year 2000, only the first 65k code points were in use. And then we added more over time.
VCS-2 says, 'hey! use only 2 bytes i.e. 2 bytes = 16 bits for every single codepoint'. With VCS-2, we just need 16-bit chunks.And it was okay for back then, but today we need more.
 Back then, symbols with larger bits didn't exist, but now it does. So, we just can't use VCS-2. Fortunately, UTF-16 allows us to do that.
Back then, symbols with larger bits didn't exist, but now it does. So, we just can't use VCS-2. Fortunately, UTF-16 allows us to do that.
So, UTF-16 is not just the same thing as VCS-2, although they try to use '16' bits. To remedy this, we came up with a plan called surrogate pairs.
Let's see, what's 'surrogate pairs'!? UTF-16 outlines it as follows:
Pretend a block that contains the first ~65k codepoints( the one we can convey with 16 bits).
 Now, we can split these ~2k codepoints in half to make two groups.
Now, we can split these ~2k codepoints in half to make two groups.
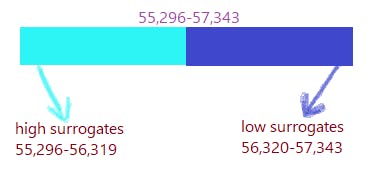
But why do we care?These are reserved for UTF-16. If, a codepoint is too large for 16-bits, we represent it with surrogate pairs:one high, one low.
Let's see algorithm for surrogate pairs. Let's run through the algorithm for 😊.
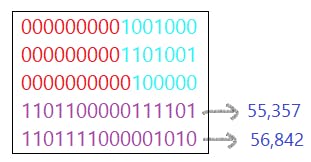
Step1: Get the code point for 😊 in binary.
😊 = 128,522
Step2: Subtract 65,536 from code point for 😊.
128,522-65,536 = 62,986
Step3: Convert the result to binary(20 digit binary number).
62,986 = 00001111011000001010
Step4: Divide it into half i.e. get first and last ten digits.
 Step5: Add each number to the start of their surrogate range.
Step5: Add each number to the start of their surrogate range.
55296 + 61 = 55,357
56320 + 522 = 56,842
And there you have it.
 And this is more space efficient than UTF-32. But, there might be still a room for improvement. Thus came UTF-8.
And this is more space efficient than UTF-32. But, there might be still a room for improvement. Thus came UTF-8.
So, let's see what's UTF-8!? Suppose, what if we were limited to 8 bits. Let's take the same example and see what happens!
 So, do we reserve the characters again!?
There aren't enough bits!
So, do we reserve the characters again!?
There aren't enough bits!
UTF-8 working is based on a series of rules/cases. Let's go through them:
For any character get it's code point.
Case1: code point < 128
do: append with '0' until 8 bits.
Case2: 128 <= code point < 2048
do: append with '0' until 11 bits.
first byte= '110' + first 5 bits
second byte= '10' + next 6 bits
Case3: 2048 <= code point < 65,536
do: append with '0' until 16 bits.
first byte= '1110' + first 4 bits
second and third byte= '10' + next 6 bits
Case4: 65,536 <= code point <
do: append with zero until '21' bits.
first byte: '11110' + first 3 bits
2nd, 3rd & 4th byte= '10' + next 6 bits
Let's take the same example of: Hi 😊
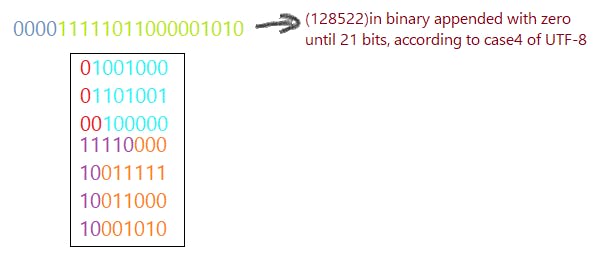
This is the most space efficient from others and therefore for the same reason is the most used.
Now, all that we know that what is encoding and how it's helpful, let's move onto last topic encodeURI().
So, what does the term encodeURI() mean!?
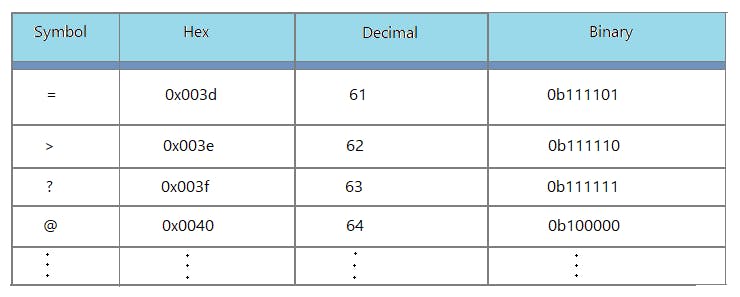
encodeURI() encodes all characters except A-Z a-z 0-9 ; , / ? : @ & = + $ - _ . ! ~ * ' ( ) #
Thanks for giving it a read. I hope this might have helped you! 😊
Will be back with more blogs...See yaa 😉!!
till then stay safe and healthy, study more, share more, gain more and grow more!!🤗